SQL — Modèle, requêtes, qualité & pipeline
Exemples pédagogiques sur un jeu e-commerce fictif (CH/EU) couvrant 2019–2024. L’idée n’est pas de « montrer une stack », mais d’illustrer ce que l’on peut faire avec SQL : bâtir un modèle simple, produire des agrégats lisibles, lire un plan d’exécution pour optimiser une requête (sargable), vérifier la qualité des données et suivre un pipeline en production légère.
P1 — Modélisation & requêtes métier
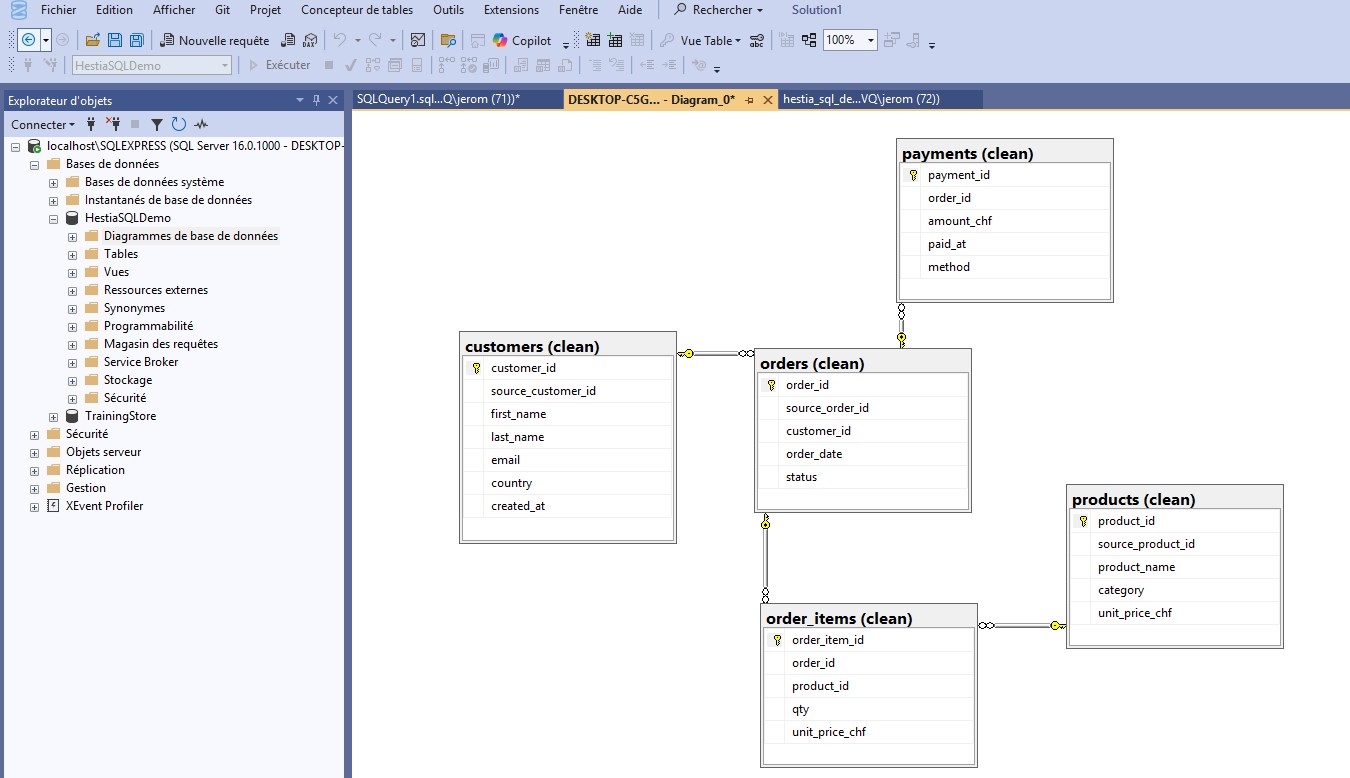
Contexte & objectifs
On part d’un modèle relationnel minimal pour illustrer ce que l’on peut faire avec SQL :
requêtes claires, indicateurs mensuels, et résultats réutilisables pour un tableau de bord.
On s’appuie sur des types explicites, des clés primaires/étrangères et des contraintes simples
(NOT NULL, CHECK).
Côté requêtes, on combine des CTE (WITH) et quelques
fonctions de fenêtre (ex. SUM() OVER) pour agréger proprement.
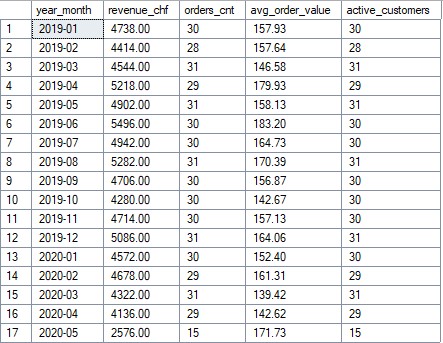
Les agrégats cibles : CA (CHF), nombre de commandes,
panier moyen et clients actifs par mois.
Agrégats mensuels (extrait)
P2 — Performance & indexation (lecture de plans)
L’objectif : réécrire une requête pour la rendre sargable (search-ARGument-able) et exploiter un index pertinent. Ici, la requête « Top clients sur période » appliquait une fonction sur la colonne de date : l’optimiseur scannait plus que nécessaire.
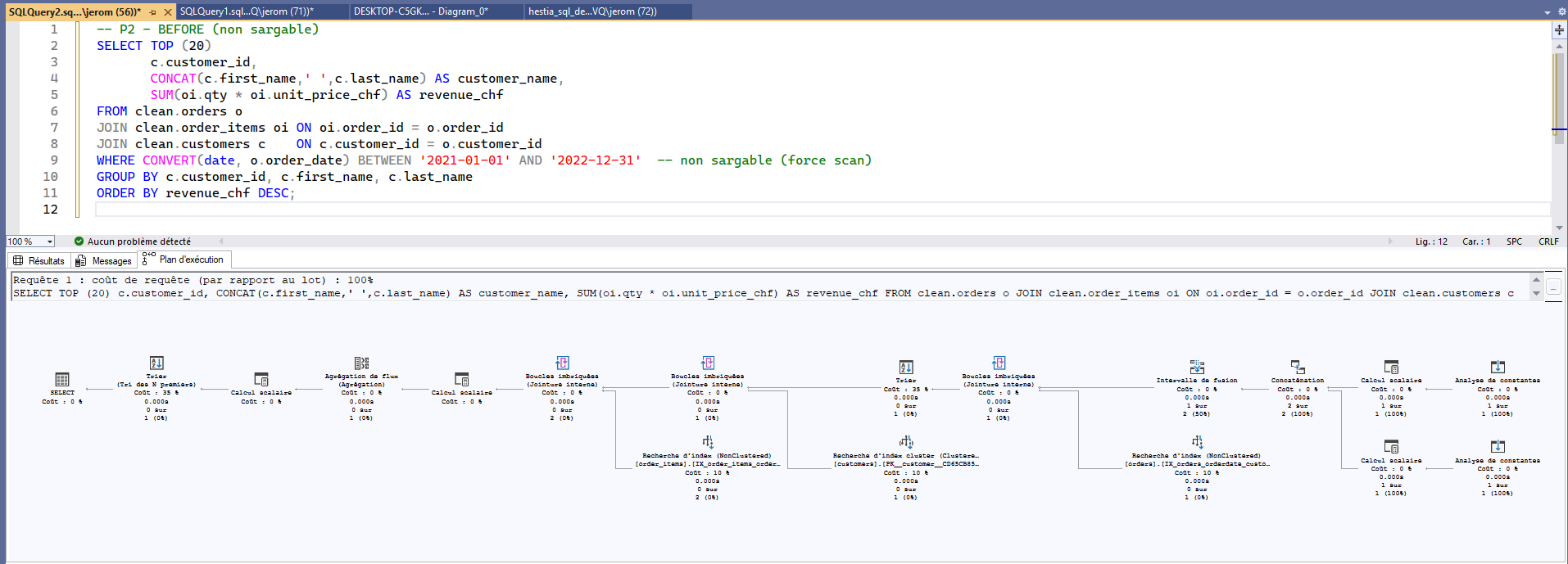
CONVERT(date, o.order_date)),
l’index ne peut pas être utilisé efficacement → scan inutilement large.
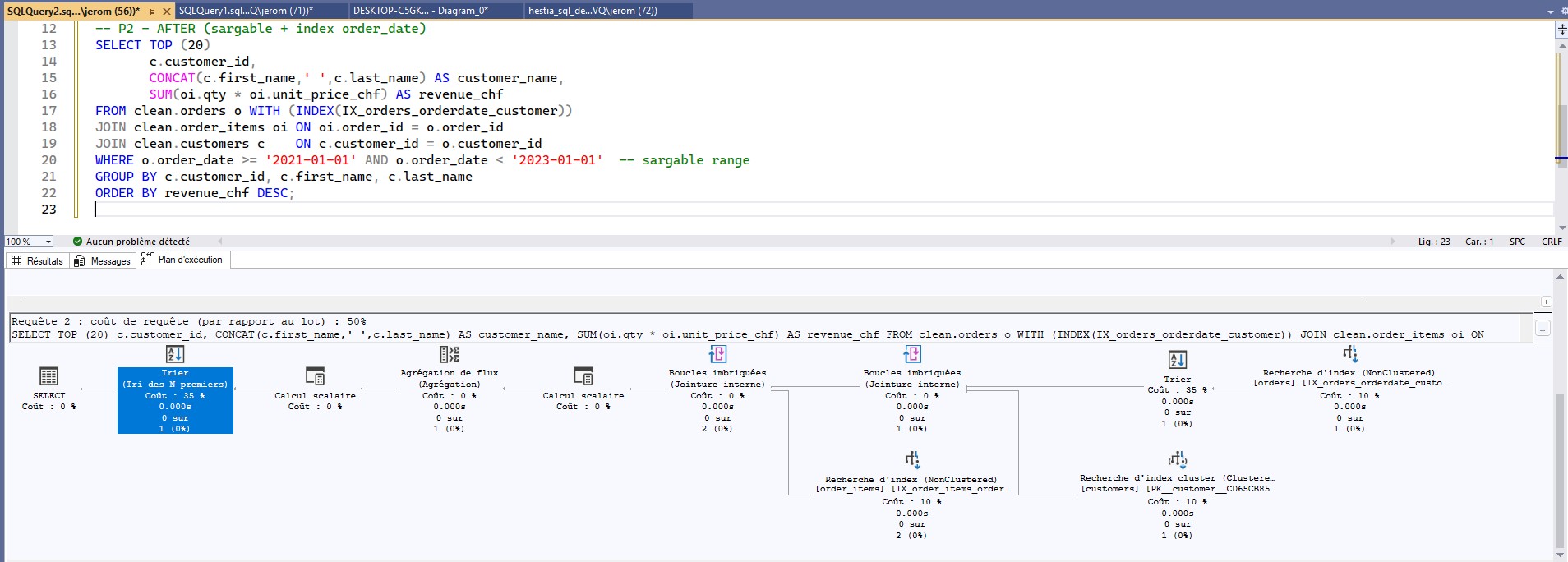
o.order_date >= '2021-01-01' AND o.order_date < '2023-01-01') +
index composé (order_date, customer_id) : plan plus léger, tri plus économique.
Bonnes pratiques : limiter les colonnes sélectionnées, préférer EXISTS à
IN quand utile, pré-agréger si nécessaire, et lire le plan
(coûts, opérateurs).
P3 — Qualité & fiabilité des données
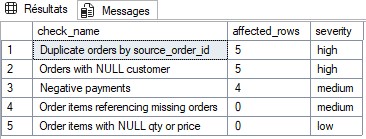
Voici ce que l’on peut faire avec SQL pour fiabiliser un jeu de données :
règles de qualité (doublons, NULL, références orphelines, montants négatifs),
mise en forme homogène et priorisation des corrections.
Une vue consolide les résultats pour les exposer à un tableau de bord
ou à des notifications.
- Règles simples et explicites (clé composite, contraintes
CHECK). - Priorisation par sévérité pour traiter d’abord l’impact métier.
- Exemples de corrections possibles (UPDATE/DELETE sécurisés).
P4 — ETL SQL léger & journal d’exécution
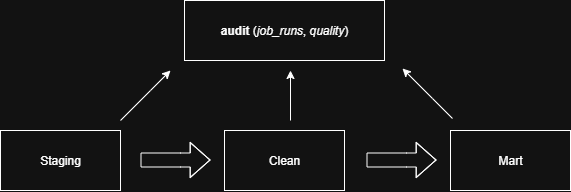
Un flux SQL « léger » reste lisible et idempotent : chargements incrémentaux, MERGE/UPSERT, clés techniques, horodatage. La planification peut se faire via CRON/Azure DevOps à 08:30 CET, avec relance en cas d’échec.
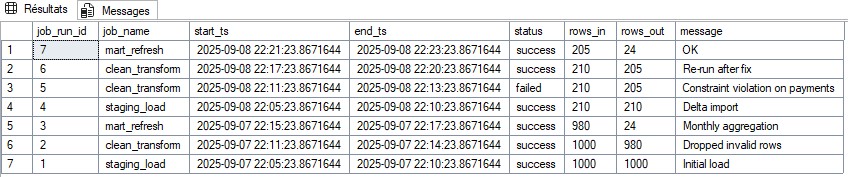
job_runs) : start/end-ts, status, rows_in/out, message.
Exemple pédagogique : ré-exécution après correction, contrainte sur paiements négatifs, delta import, etc.
Sortie attendue : un pipeline simple, observable et traçable, prêt à être branché sur un dashboard opérationnel.